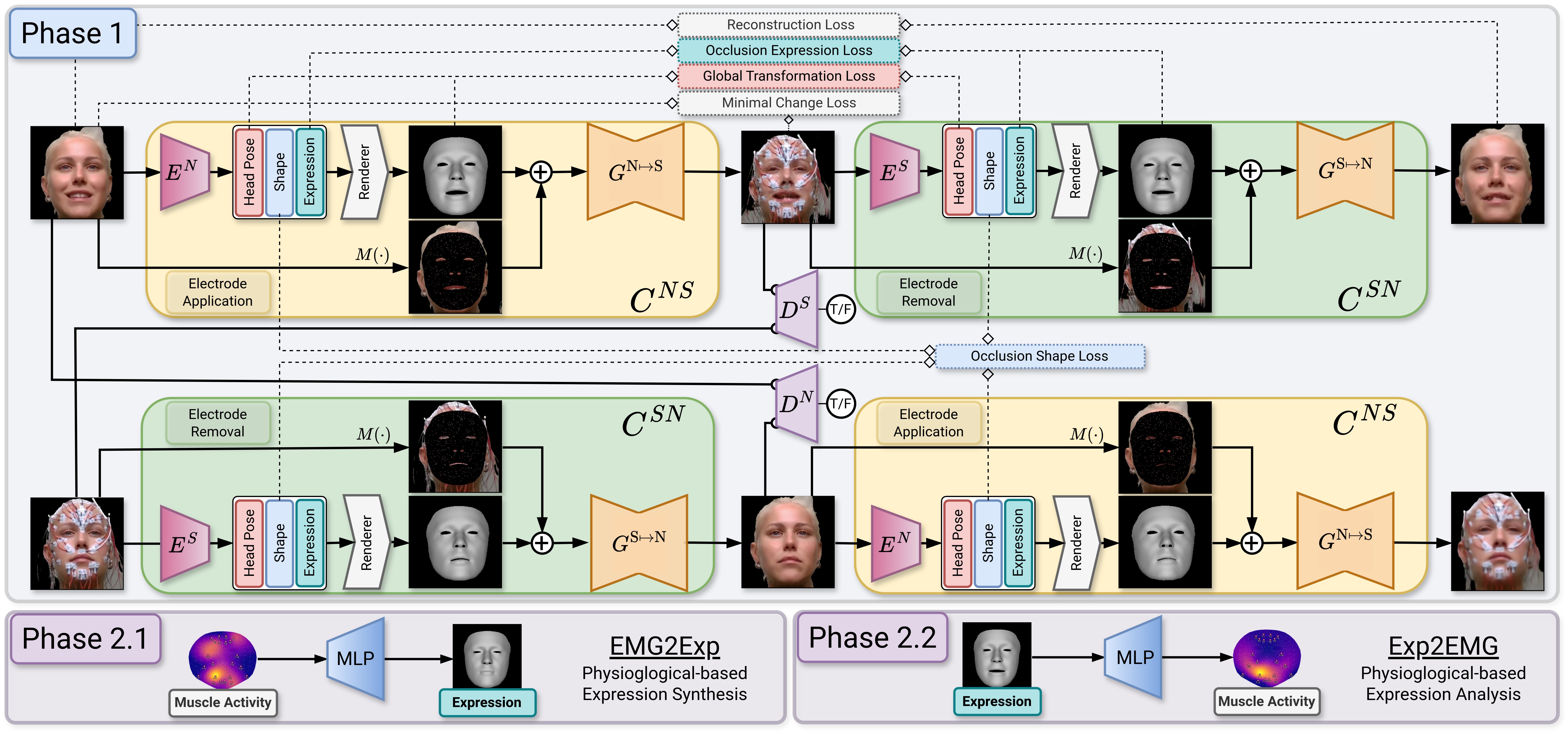
Bridging the gap between mimics and muscles: Our method EIFER utilizes neural unpaired image-to-image translation to decouple facial geometry and appearance for muscle-activity-based expression synthesis and electrode-free facial electromyography.
Main Insights

Facial Geometry Reconstruction
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. It correctly captures the expression, identity, and pose of the subject. Existing methods struggle to align the face due to already misaligned landmark placements. Further, the identity parameters diverge even with the same person, making them unsuitable for our task.
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. It correctly captures the expression, identity, and pose of the subject. Existing methods struggle to align the face due to already misaligned landmark placements. Further, the identity parameters diverge even with the same person, making them unsuitable for our task.

Facial Appearance Reconstruction
Our method separates the facial appearance from the geometry, allowing for faithful reconstruction of the skin texture, lighting, and occluded electrodes. While existing methods inherently restore the occluded regions due to the utilized appearance model, our method creates more photorealistic results due to the adversarial cyclic training.
Our method separates the facial appearance from the geometry, allowing for faithful reconstruction of the skin texture, lighting, and occluded electrodes. While existing methods inherently restore the occluded regions due to the utilized appearance model, our method creates more photorealistic results due to the adversarial cyclic training.
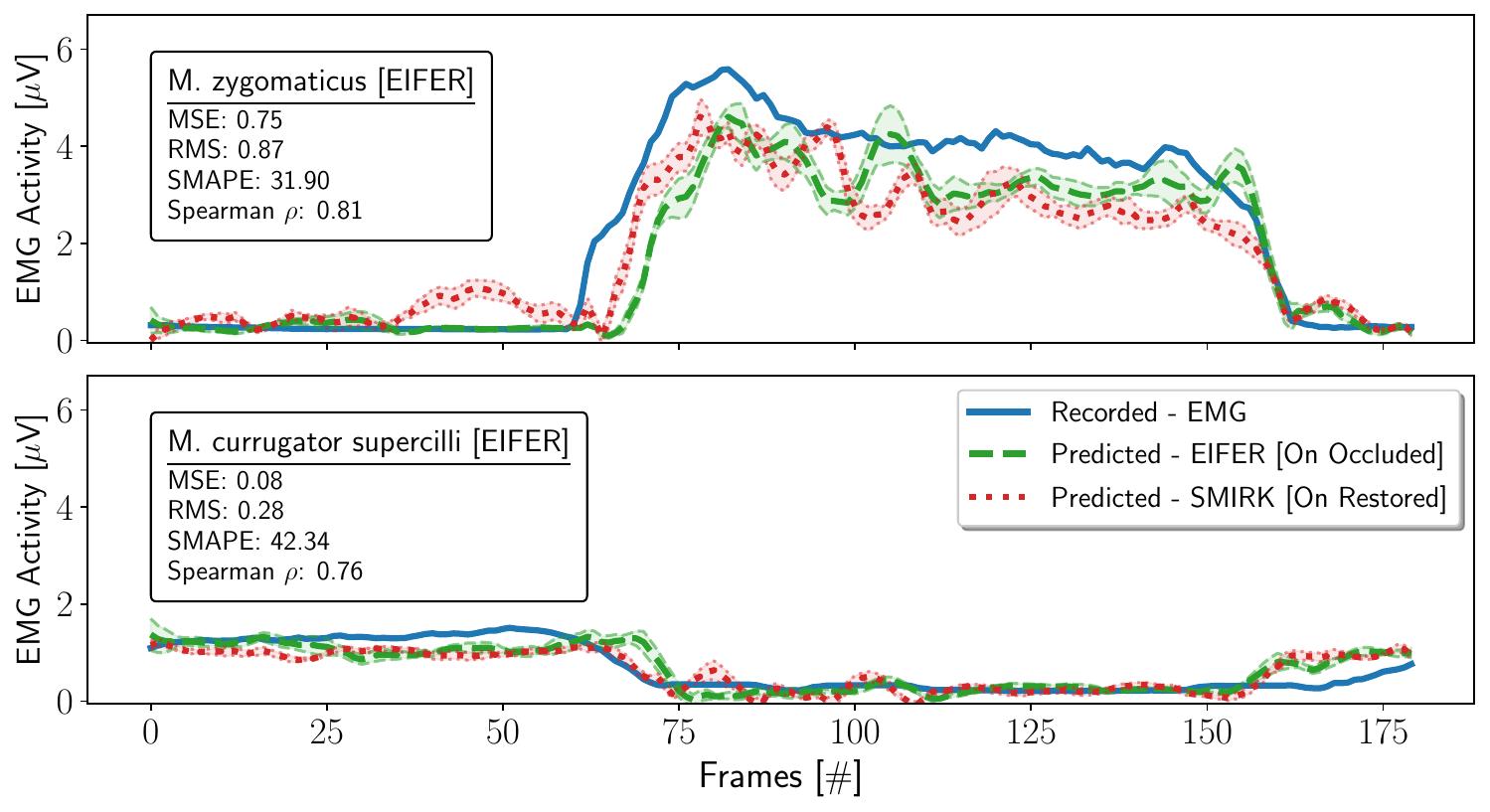
Electrode-Free Facial EMG
Our method allows for the prediction of muscle activity based on observed facial expressions, this is a new paradigm for electrode-free facial electromyography. This enables the reconstruction of muscle activity without the need for electrodes, providing a new way to analyze facial expressions. We demonstrate that our method can predict muscle activity from observed expressions and synthesize expressions based on muscle activity. We provide next to EIFER several Exp2EMG models for existing extractors like DECA, EMOCAv2, SMIRK,Deep3DFace, and FOCUS. Hence, both FLAME and BFM expression spaces are connected to the muscle activity.
Our method allows for the prediction of muscle activity based on observed facial expressions, this is a new paradigm for electrode-free facial electromyography. This enables the reconstruction of muscle activity without the need for electrodes, providing a new way to analyze facial expressions. We demonstrate that our method can predict muscle activity from observed expressions and synthesize expressions based on muscle activity. We provide next to EIFER several Exp2EMG models for existing extractors like DECA, EMOCAv2, SMIRK,Deep3DFace, and FOCUS. Hence, both FLAME and BFM expression spaces are connected to the muscle activity.

Expression Synthesis
In the second phase of EIFER we learn to synthesize facial expressions based on muscle activity. This allows to generate expression based solely on muscle activity and provides a new way to analyze facial expressions, especially interesting for possible advances in camera-free animation captures. While EIFER creates the most realistic results, we will also publish EMG2Exp of MC-CycleGAN+Model combinations. Therefore, both the expression space of both FLAME and BFM are now connected to the muscle activity.
In the second phase of EIFER we learn to synthesize facial expressions based on muscle activity. This allows to generate expression based solely on muscle activity and provides a new way to analyze facial expressions, especially interesting for possible advances in camera-free animation captures. While EIFER creates the most realistic results, we will also publish EMG2Exp of MC-CycleGAN+Model combinations. Therefore, both the expression space of both FLAME and BFM are now connected to the muscle activity.

More Geometry Examples - Face At Rest
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the face at rest, where the subject is not performing any facial expression.
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the face at rest, where the subject is not performing any facial expression.

More Geometry Examples - Eyes closed tightly
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject closing their eyes tightly, which is a challenging due to the similarity of a soft eye closure or rapid blinking.
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject closing their eyes tightly, which is a challenging due to the similarity of a soft eye closure or rapid blinking.

More Geometry Examples - Smile Open
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject smiling with their mouth open, which is a challenging as the mouth inside should not be visible.
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject smiling with their mouth open, which is a challenging as the mouth inside should not be visible.

More Geometry Examples - Snarl
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject snarling, which is a challenging expression due to the wrinkles and the mouth opening downwards.
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject snarling, which is a challenging expression due to the wrinkles and the mouth opening downwards.

More Geometry Examples - Nose wrinkling
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject wrinkling their nose, which is a challenging expression due to the wrinkles only the nose bridge and forehead (glabella) should be affected.
Our method EIFER faithfully reconstructs the facial geometry under strong sEMG electrode occlusion. This example shows the subject wrinkling their nose, which is a challenging expression due to the wrinkles only the nose bridge and forehead (glabella) should be affected.